반응형
안녕하세요. Visul Studio에서 GPU 정보를 보는 포스팅입니다. 매우 간단합니다.
CUDA 설치과정에서 Visual Studio에 설치되는 NSIGHT를 통해 GPU 사양확인이 가능합니다.
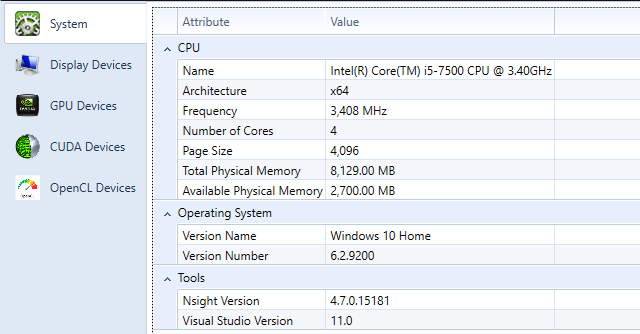
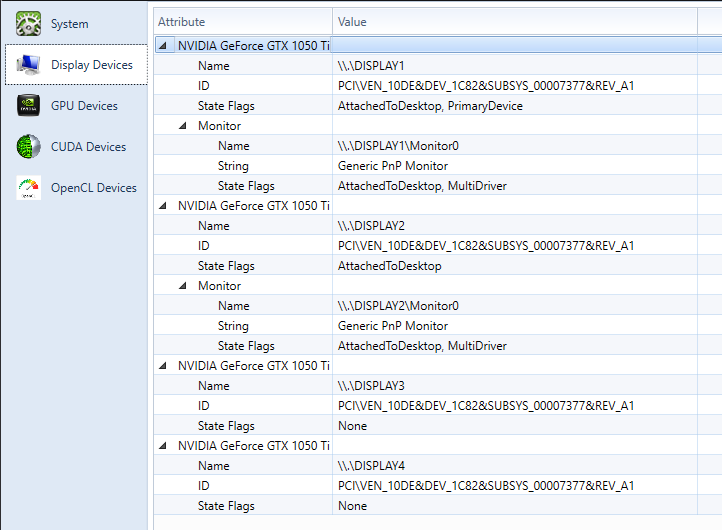
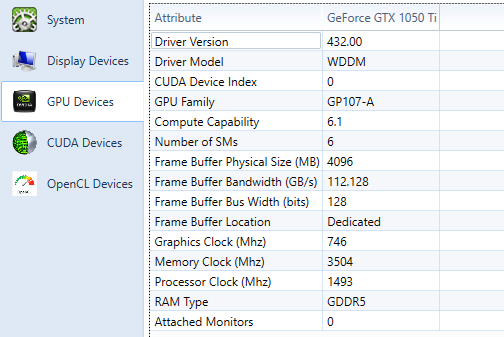
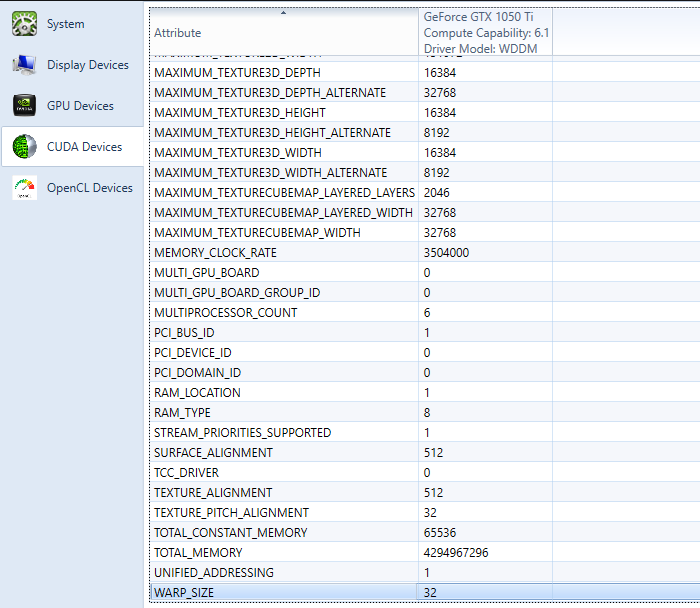
아래 해당 코드는 CUDA Device정보를 얻어서 다음과 같이 표현할수 있습니다. 여기서 NSIGHT에서 확인한 CUDA Device가 모두 있는거 같네요^^
void CGPUSolid::GpuInfoPrint()
{
cudaDeviceProp prop;
int count = 0;
cudaGetDeviceCount( &count );
for (int i=0; i< count; i++)
{
cudaGetDeviceProperties( &prop, i );
printf( " --- General Information for device %d ---\n", i );
printf( "Name: %s\n", prop.name );
printf( "Compute capability: %d.%d\n", prop.major, prop.minor );
printf( "Clock rate: %d\n", prop.clockRate );
printf( "Device copy overlap: " );
if (prop.deviceOverlap)
printf( "Enabled\n" );
else
printf( "Disabled\n");
printf( "Kernel execution timeout : " );
if (prop.kernelExecTimeoutEnabled)
printf( "Enabled\n" );
else
printf( "Disabled\n" );
printf( "\n" );
printf( " --- Memory Information for device %d ---\n", i );
printf( "Total global mem: %ld\n", prop.totalGlobalMem );
printf( "Total constant Mem: %ld\n", prop.totalConstMem );
printf( "Max mem pitch: %ld\n", prop.memPitch );
printf( "Texture Alignment: %ld\n", prop.textureAlignment );
printf( "\n" );
printf( " --- MP Information for device %d ---\n", i );
printf( "Multiprocessor count: %d\n", prop.multiProcessorCount );
printf( "Shared mem per mp: %ld\n", prop.sharedMemPerBlock );
printf( "Registers per mp: %d\n", prop.regsPerBlock );
printf( "Threads in warp: %d\n", prop.warpSize );
printf( "Max threads per block: %d\n", prop.maxThreadsPerBlock );
printf( "Max thread dimensions: (%d, %d, %d)\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2] );
printf( "Max grid dimensions: (%d, %d, %d)\n",prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2] );
printf( "\n" );
}
}
cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device); 함수로 얻어 올수 있는 구조체입니다. 해당 구조체는 driver_types.h에 포함된 구조체입니다.
struct __device_builtin__ cudaDeviceProp
{
char name[256]; /**< ASCII string identifying device */
size_t totalGlobalMem; /**< Global memory available on device in bytes */
size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
int regsPerBlock; /**< 32-bit registers available per block */
int warpSize; /**< Warp size in threads */
size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */
int maxThreadsPerBlock; /**< Maximum number of threads per block */
int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */
int maxGridSize[3]; /**< Maximum size of each dimension of a grid */
int clockRate; /**< Clock frequency in kilohertz */
size_t totalConstMem; /**< Constant memory available on device in bytes */
int major; /**< Major compute capability */
int minor; /**< Minor compute capability */
size_t textureAlignment; /**< Alignment requirement for textures */
size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */
int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */
int multiProcessorCount; /**< Number of multiprocessors on device */
int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */
int integrated; /**< Device is integrated as opposed to discrete */
int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */
int computeMode; /**< Compute mode (See ::cudaComputeMode) */
int maxTexture1D; /**< Maximum 1D texture size */
int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */
int maxTexture1DLinear; /**< Maximum size for 1D textures bound to linear memory */
int maxTexture2D[2]; /**< Maximum 2D texture dimensions */
int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */
int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */
int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */
int maxTexture3D[3]; /**< Maximum 3D texture dimensions */
int maxTexture3DAlt[3]; /**< Maximum alternate 3D texture dimensions */
int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */
int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */
int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */
int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */
int maxSurface1D; /**< Maximum 1D surface size */
int maxSurface2D[2]; /**< Maximum 2D surface dimensions */
int maxSurface3D[3]; /**< Maximum 3D surface dimensions */
int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */
int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */
int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */
int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */
size_t surfaceAlignment; /**< Alignment requirements for surfaces */
int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */
int ECCEnabled; /**< Device has ECC support enabled */
int pciBusID; /**< PCI bus ID of the device */
int pciDeviceID; /**< PCI device ID of the device */
int pciDomainID; /**< PCI domain ID of the device */
int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */
int asyncEngineCount; /**< Number of asynchronous engines */
int unifiedAddressing; /**< Device shares a unified address space with the host */
int memoryClockRate; /**< Peak memory clock frequency in kilohertz */
int memoryBusWidth; /**< Global memory bus width in bits */
int l2CacheSize; /**< Size of L2 cache in bytes */
int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */
int streamPrioritiesSupported; /**< Device supports stream priorities */
int globalL1CacheSupported; /**< Device supports caching globals in L1 */
int localL1CacheSupported; /**< Device supports caching locals in L1 */
size_t sharedMemPerMultiprocessor; /**< Shared memory available per multiprocessor in bytes */
int regsPerMultiprocessor; /**< 32-bit registers available per multiprocessor */
int managedMemory; /**< Device supports allocating managed memory on this system */
int isMultiGpuBoard; /**< Device is on a multi-GPU board */
int multiGpuBoardGroupID; /**< Unique identifier for a group of devices on the same multi-GPU board */
};
반응형